
Pubblicato il 13 gennaio 2017 su TennisAbstract – Traduzione di Edoardo Salvati
// Quando un errore è forzato? Se, per rispondere alla domanda, si ipotizza di sviluppare un algoritmo, la situazione diventa rapidamente ingestibile. Bisognerebbe tenere conto della posizione del giocatore, della velocità, angolo e rotazione del colpo, della velocità della superficie e forse di qualcos’altro. Ci sono errori chiaramente individuabili come forzati e non forzati, ma molti finiscono in un’ambigua terra di mezzo.
Molte delle statistiche relative agli errori non forzati mostrate durante una telecronaca o di riepilogo alla fine della partita sono conteggiate a mano.
Eccessiva semplificazione
Il valutatore riceve delle istruzioni preliminari e prende nota di ogni tipo di errore. Se si dovesse ridurre l’algoritmo umano di conteggio a una sola regola, la sua definizione sarebbe simile a: “Ci si aspetta che un professionista medio sia in grado di non sbagliare quel colpo?”. Ci sono valutatori che limitano il computo degli errori non forzati escludendo errori come le risposte al servizio, i colpi a rete o i tentativi di passante.
Naturalmente, qualsiasi intenzione di raggruppare i colpi sbagliati solo in due categorie sarebbe frutto di eccessiva semplificazione. E non credo che il mio sia un punto di vista estremo.
Molti commentatori di tennis danno credito a questa posizione quando spiegano che l’errore non forzato di un giocatore “non la dice tutta”, o un’altra espressione a effetto di questa natura.
Ho scritto in passato dei limiti dello spesso citato rapporto tra vincenti ed errori non forzati e della somiglianza tra gli errori non forzati e la giustamente criticata statistica della media difensiva nel baseball.
Si immagini per un momento di avere a disposizione dei dati migliori con cui lavorare – perché ad esempio quelli di Hawk-Eye non sono protetti in cassaforte – e di poter elaborare una metodologia di identificazione degli errori più precisa.
In primo luogo, invece di considerare solo gli errori, è più istruttivo classificare i potenziali colpi in tre categorie: colpi rimessi in gioco, errori (che specificheremo meglio più avanti) e vincenti dell’avversario.
Sei riuscito a giocare il colpo, l’hai sbagliato o non hai nemmeno visto la pallina?
L’errore forzato di un giocatore corrisponde al colpo rimesso in gioco dall’avversario (specialmente se il giocatore è Bernard Tomic e se l’avversario è Andy Murray). Diventa quindi necessario valutare l’intero spettro di possibili esiti di ciascun potenziale colpo.
La chiave per acquisire conoscenza diretta dalle statistiche di tennis è di raffinare il contesto di riferimento con altre informazioni a disposizione.
Ad esempio confrontare le statistiche di un giocatore con il rendimento di un giocatore medio del circuito, o contrapporle a quelle derivanti dall’ultima partita giocata con caratteristiche simili. Per gli errori la questione non è diversa.
Kasatkina vs Kerber Sidney 2017
Ecco un facile esempio. Nel sesto game dei sedicesimi di finale contro Darya Kasatkina al torneo di Sidney 2017, Angelique Kerber ha colpito un dritto lungolinea come nella foto:
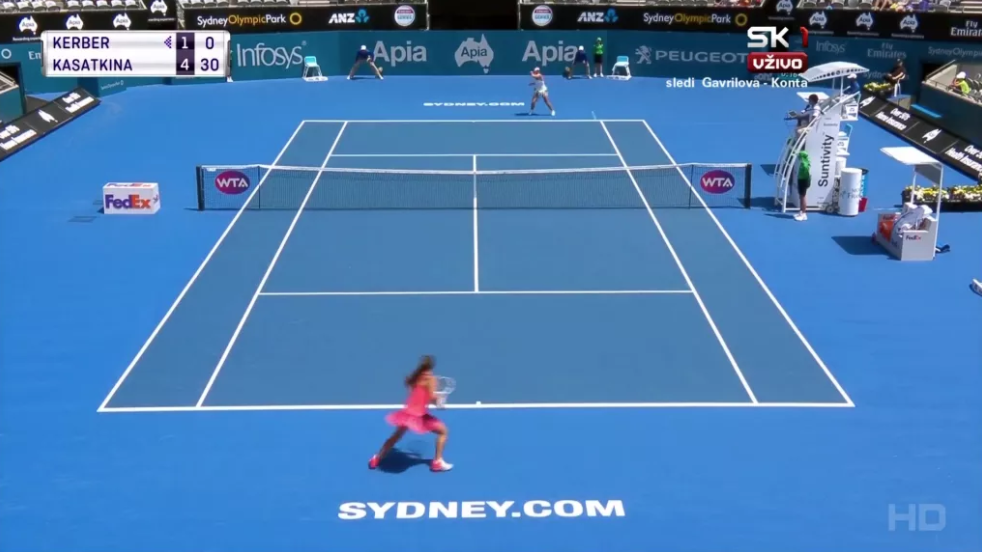
Grazie al Match Charting Project, siamo in possesso di dati su 350 dritti lungolinea di Kerber, per cui sappiamo che ottiene un vincente il 25% delle volte, mentre la sua avversaria colpisce un errore forzato un altro 9% delle volte.
Diciamo che un ulteriore 11% si trasforma in errori non forzati e arriviamo a un profilo di quanto succede abitualmente quando Kerber cerca il lungolinea: 25% vincenti, 20% errori, 55% colpo rimesso in gioco.
Si potrebbe approfondire ancora e stabilire che il 55% dei colpi rimessi in gioco consiste in un 30% che determina la conquista del punto da parte di Kerber rispetto a un 25% in cui il punto lo ha perso.
In questo caso, Kasatkina è riuscita ad arrivarci con la racchetta, sbagliando però un colpo che molti valutatori sarebbero d’accordo nel giudicare un errore forzato:
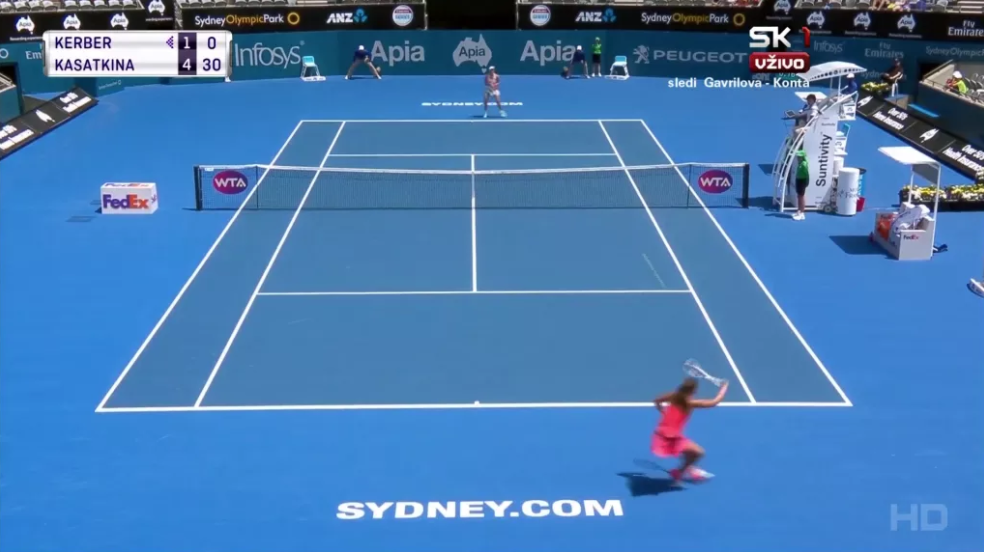
Questa singola occorrenza – un errore forzato di Kasatkina contro un tipo di colpo offensivo molto efficace – non rivela nulla in sé e per sé. Ipotizziamo però di aver tenuto traccia di 100 tentativi di replica a un dritto lungolinea di Kerber da parte di molteplici giocatrici.
Potremmo scoprire che Kasatkina concede 35 vincenti su 100, o che Simona Halep concede solo 15 vincenti e rimette in gioco 70 colpi, o ancora che Anastasia Pavlyuchenkova commette un errore 30 volte su 100 tentativi.
La mia tesi
Con più statistiche granulari, possiamo inserire gli errori in un contesto concreto. Invece di esprimere un giudizio sulla difficoltà di un determinato colpo (o affidarsi a un valutatore per stabilirlo), è concepibile lasciare che sia un algoritmo a eseguire il lavoro su 100 colpi, per verificare se una giocatrice riesce a raggiungere più colpi della giocatrice media o se sta facendo più errori di quanto non faccia abitualmente.
Il presente e il futuro
Nel precedente esempio, ho omesso molti dettagli importanti. Nel confrontare l’errore di Kasatkina con un centinaio di altri dritti lungolinea di Kerber, non sappiamo se il colpo sia stato più difficile del solito, se sia stato piazzato più accuratamente all’incrocio, se Kasatkina fosse in una posizione di campo migliore di quella di una giocatrice media nella stessa dinamica di gioco o se fosse diversa la velocità della superficie.
È probabile che su un centinaio di dritti lungolinea siano parametri che si annullino. Ma nella partita in questione, Kerber ne ha colpiti solo 18. Se, tipicamente, in una partita al meglio dei tre set si raccoglie materiale per qualche centinaio di colpi, con questo tipo di analisi non si riesce ad andare oltre.
In futuro, un ideale algoritmo di classificazione degli errori potrà fare molto di più. Considererà tutte le variabili che ho elencato (e, senza dubbio, altre) e, per ogni colpo, calcolerà la probabilità di differenti esiti.
Nel momento di gioco della prima immagine, cioè quando la pallina ha appena abbandonato la racchetta di Kerber, con Kasatkina nella metà di campo più lontana, potremmo stimare una probabilità di vincente del 35%, una di errore del 25% e un 40% di probabilità che venga rimessa in gioco. In funzione del tipo di analisi che stiamo facendo, potremmo calcolare quei numeri per la giocatrice media del circuito o per Kasatkina stessa.
Sono stime con cui potremmo, di fatto, assegnare un “valore” agli errori. Continuando con l’esempio, l’algoritmo prevede solo un 40% di probabilità per Kasatkina di rimettere la pallina in gioco. In confronto, un colpo in uno scambio ha in media il 90% di probabilità di essere rimesso in gioco.
Suddivisioni più accurate
Invece di dover catalogare gli errori come “forzati” e “non forzati”, saremmo in grado a nostro piacimento di operare una suddivisione più accurata, come ad esempio raggruppare i potenziali colpi in quintili.
Potremmo ad esempio calcolare se Murray riesce a rimettere in gioco più spesso rispetto a Novak Djokovic la maggior parte dei colpi che non hanno replica. Anche se già abbiamo un’idea al riguardo, finché non abbiamo stabilito con precisione in cosa consista il quintile (o quartile o qualsiasi altro) non possiamo nemmeno iniziare a dimostrarla.
Sarebbe un tipo di analisi accattivante anche per quegli appassionati solitamente non interessati alle statistiche aggregate. Pensiamo alla facoltà di un commentatore di isolare uno specifico colpo di Murray e poter dire che avesse solo il 2% di probabilità di rimettere in gioco la pallina in quella situazione.
In scambi con continui capovolgimenti di fronte, è un metodo in grado di generare un grafico di probabilità di vittoria per ogni singolo punto, un’immagine capace di comunicare immediatamente quanto abbia dovuto faticare un giocatore per rientrare in uno scambio che sembrava ormai perso.
La tecnologia è già disponibile
Fortunatamente, la tecnologia per raggiungere questo livello esiste già. Analisti con accesso a sottoinsiemi di dati Hawk-Eye hanno incominciato a individuare i fattori che incidono su aspetti come la scelta del colpo.
Il software “SmartCourts” di Playsight distingue gli errori tra forzati e non forzati quasi in tempo reale, lasciando intendere di far leva su un meccanismo molto più sofisticato ma non visibile, anche se nemmeno gli algoritmi di Intelligenza Artificiale sono esenti da occasionali cantonate.
Un’altra possibile strada è di applicare algoritmi di apprendimento automatico a enormi quantità di partite, facendo in modo che siano essi stessi a determinare i migliori fattori predittivi di vincenti, errori e altri esiti di un colpo.
Un giorno gli appassionati di tennis guarderanno con meraviglia alla scarsa conoscenza statistica nello sport del 21° secolo. ◼︎
